Most AI report tools work the same way: you select a topic, a long prompt runs against whatever context is available, and markdown comes back. The output is coherent. It's readable. It might even surface something useful.
It is not analyst-grade competitive intelligence.
We know, because that's where we started.
The first version of Innovista's report engine was a single, carefully constructed prompt fed into a capable model with a curated context window. The output was technically correct and strategically shallow — the kind of analysis that confirms what you already suspected without telling you anything you didn't know. No senior strategist would sign off on it.
The problem wasn't the model. It was the assumption that a single generation pass could replicate a process that, done well, involves five distinct roles.
How a Skilled Analyst Actually Writes a CI Report
A senior CI analyst doesn't write a 10,000-word report in one pass. The process is sequential and role-separated:
They plan first — what are the right questions for this report type? What sections does a Deep Dive on a semiconductor company need that a Supply Chain report doesn't?
They research independently per section — the HBM supply chain evidence doesn't get mixed with the financial structure evidence. Each section has its own evidence base.
They synthesize section by section — with evidence in hand, they write. Not summarize: synthesize. They surface the tension between a company's stated roadmap and what the supply chain signals actually show.
It goes through review — a second set of eyes checks whether the analytical depth is real, whether the factual claims hold, whether the forward-looking conclusions are grounded.
Then it gets packaged and delivered.
That's five roles. Collapsing them into one prompt loses the structure, the independence between sections, and the review step that makes the output trustworthy.
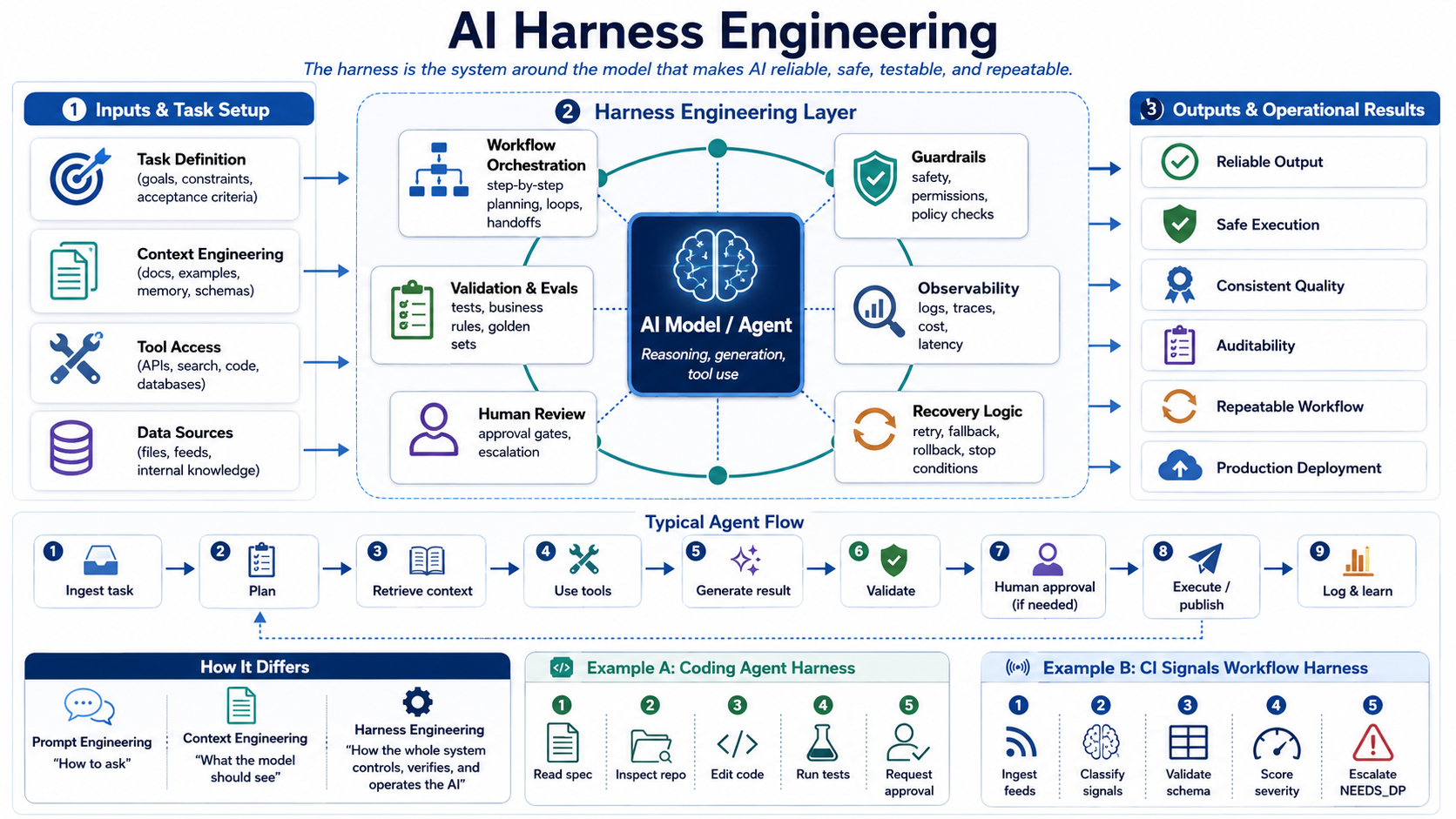
The Five-Agent Pipeline
Innovista's report engine runs five role-separated agents — each with its own system prompt, its own context, and its own responsibility.
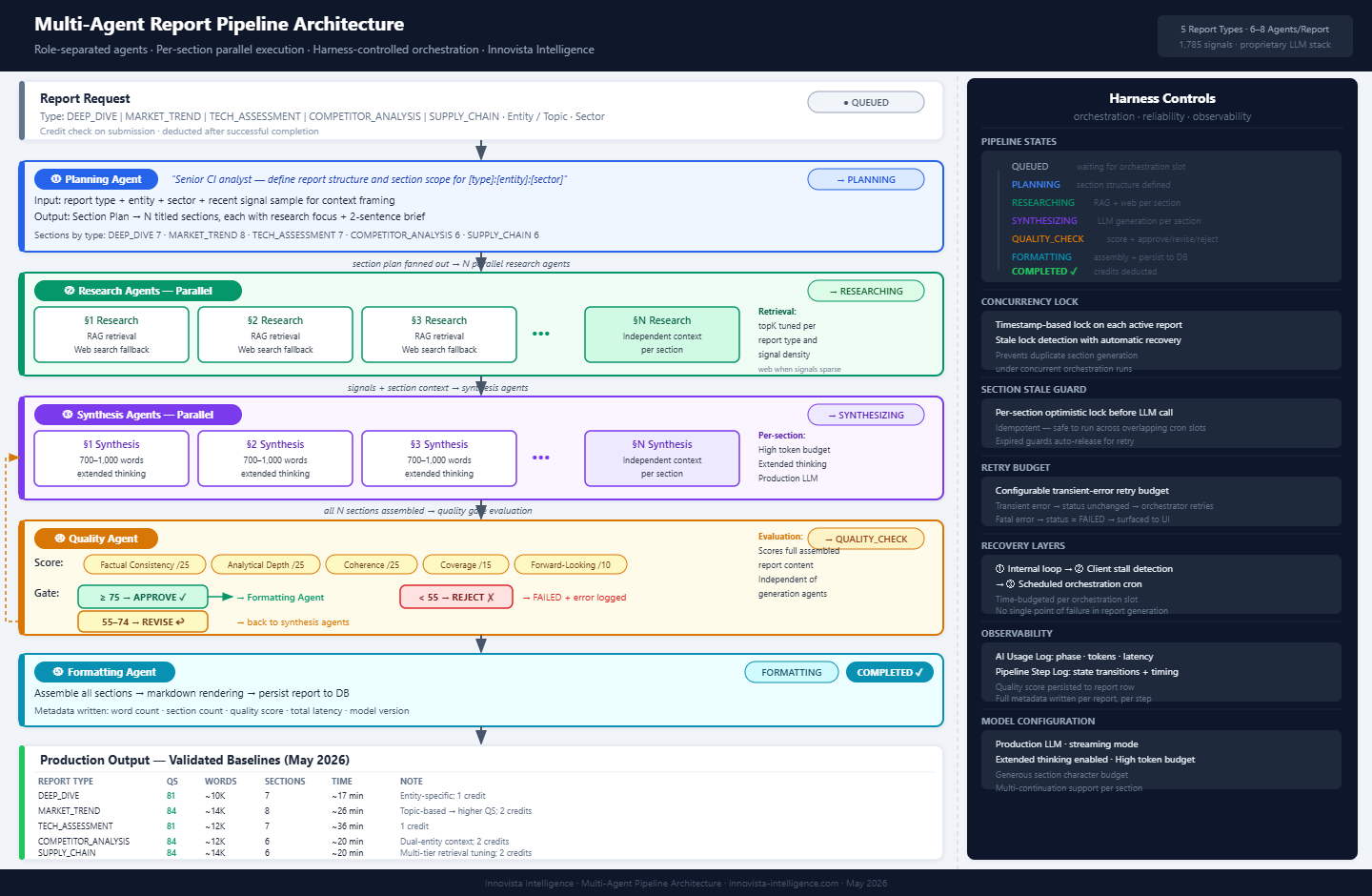
① Planning Agent
The pipeline starts with planning, not generation. The Planning Agent reads the report request — type, entity, sector — and produces a Section Plan: N sections (6–8 depending on type), each with a research focus and a two-sentence brief. This plan is the contract that every downstream agent works from.
Report type matters here. A Deep Dive on a company has different sections than a Market Trend analysis or a Competitor Analysis. The Planning Agent structures accordingly, so the research and synthesis layers receive the right framing from the start.
② Research Agents — Running in Parallel
One Research Agent spins up per section, all running simultaneously. Each agent is fully independent: it queries the signal database using vector similarity search scoped to that section's research focus, falls back to real-time web search when signal density is low, and packages a context bundle for synthesis. The retrieval strategy is tuned per report type — what drives quality in a Supply Chain report is not the same as what drives quality in a Market Trend.
Parallelism is the key architectural decision. Six sections researched sequentially would take six times as long. With parallel agents, all sections are researched simultaneously, and the research phase takes the time of one.
③ Synthesis Agents — Also in Parallel
Each section's research bundle is handed off to a Synthesis Agent — one per section, all running simultaneously. Each agent works with extended thinking enabled and a high token budget. The target is 700–1,000 words per section: long enough to go deep, short enough to stay focused.
Extended thinking isn't cosmetic at this depth. A synthesis agent reasoning through the competitive implications of TSMC's advanced packaging roadmap against conflicting supply chain signals needs to work through multiple interpretations before committing to an analytical angle. That reasoning process is what separates synthesis from summary.
④ Quality Agent
Once all sections are written, they are assembled and handed to the Quality Agent — which has not seen any of the generation work and approaches the report cold. It evaluates across five dimensions: Factual Consistency, Analytical Depth, Coherence, Coverage, and Forward-Looking Insight.
The gate is strict. Score 75 or above: approved, proceed to formatting. Score 55–74: returned to the synthesis layer for revision. Score below 55: rejected and logged as failed.
This is the step most single-prompt systems skip entirely. The QA gate is why our quality scores are consistent across hundreds of report runs. The pipeline cannot ship a shallow report — the Quality Agent sends it back.
⑤ Formatting Agent
The approved report is assembled, rendered to clean markdown, and persisted to the database with full metadata: word count, section count, quality score, latency, and model version.
Why Multiple Agents Produce Analyst-Grade Output
The quality improvement from a multi-agent pipeline isn't incidental — it's architectural. There are three mechanisms at work that a single-pass system structurally cannot replicate.
Context freshness per section. Language models have a well-documented attention degradation problem over long outputs: the reasoning applied to section 7 of a 10,000-word report generated in one pass is materially weaker than the reasoning applied to section 1. The model's attention is spread across everything that came before. Parallel synthesis eliminates this entirely. Each Synthesis Agent starts fresh — clean attention, scoped context, full reasoning capacity applied to one section only. Section 7 gets the same analytical depth as section 1.
Role specialization produces better outputs at every stage. A planning agent prompted specifically to structure a Competitor Analysis has no interference from synthesis concerns. A research agent scoped to a single section's retrieval question finds more precise evidence than one trying to serve an entire report. A quality agent that has never seen the generation context can evaluate the assembled report without the blind spots that come from having written it. Specialization compounds across every stage of the pipeline.
The revision loop is a built-in quality improvement mechanism — not error handling. When the Quality Agent scores a report between 55 and 74, it doesn't flag an error. It returns specific feedback to the synthesis layer for targeted revision. Reports that enter the quality gate below the approval threshold and complete a revision pass come back materially stronger — the second synthesis pass has both the original evidence and the quality agent's critique to work from. No single-prompt system has a mechanism to catch and improve its own output. The multi-agent architecture makes this possible by design.
The result is reports that read like analysis, not summaries. Sections that build on each other rather than repeating the same framing with different company names. Forward-looking conclusions that are traceable to the evidence, not extrapolated from pattern-matched training data.
The Harness Is What Makes It Reliable
Building five agents that can each do their job is the tractable part. Making the pipeline run reliably — across concurrent requests, with automatic recovery when any step stalls — is the engineering problem.
Three things we learned building the harness layer:
Parallel execution creates concurrency problems. When multiple orchestration runs can be in-flight simultaneously, you need a lock on each active report. Without it, two runs can independently pick up the same report and start generating duplicate sections. We use timestamp-based locks with stale detection: a lock held beyond a threshold is broken automatically, and the pipeline resumes from the last completed step without re-doing completed work.
Section-level idempotency is non-negotiable. Each section is independently locked before its LLM call begins. If an orchestration slot times out mid-report, the next run skips completed sections and continues from where work stopped. No duplicate generation, no wasted compute.
Three recovery layers, not one. The pipeline has an internal continuation loop for long-running sections, a client-side stall detector for sections that go quiet, and a scheduled orchestration cron that sweeps for stuck reports. Any one of them can recover a stalled pipeline. In practice, most stalls resolve before the user notices.
This is the distinction the two diagrams in this post are illustrating. Prompt engineering is how you ask a question. Context engineering is what information surrounds the question. Harness engineering is how the whole system operates — the orchestration layer, the concurrency controls, the recovery logic, the quality gate — that turns a capable model into a reliable product.
The first diagram frames the concept. The second shows what it looks like in the Innovista pipeline.
What This Produces
Validated across all five report types in May 2026, running against 1,785+ proprietary signals tracked continuously across semiconductors, EV/ADAS, and AI applications:
| Report Type | Quality Score | Words | Time |
|---|---|---|---|
| Deep Dive | 81 | ~10,000 | ~17 min |
| Market Trend | 84 | ~14,000 | ~26 min |
| Tech Assessment | 81 | ~12,000 | ~36 min |
| Competitor Analysis | 84 | ~12,000 | ~20 min |
| Supply Chain | 84 | ~14,000 | ~20 min |
Topic-based reports — Market Trend, Supply Chain, Competitor Analysis — consistently score higher than entity-specific ones. A broader, multi-source signal set forces more synthesis and less summary, which is exactly what the quality gate rewards.
Every report runs against a signal library that has been continuously tracked since September 2025. These are signals that don't exist in any public dataset and can't be reconstructed from model training weights. The grounding is structural, not prompt-level.
What This Changes
Most CI organizations have the same bottleneck: not a shortage of data, but a shortage of synthesis capacity. Signals arrive faster than analysts can process them.
A single-prompt AI report closes part of that gap. A five-agent pipeline with a quality gate closes most of it — at a quality level a single pass can't reach, in a time window a human analyst can't match, grounded in a proprietary signal library that makes hallucination on market facts structurally impossible.
The harness isn't background infrastructure. It's the product.